An Open-Source Datadog Alternative for LLM Observability
Introduction
Datadog has long been a favourite among developers for its monitoring and observability capabilities. It is most known for its logging, analytics, and performance data visualization across the entire stack of applications and infrastructure, and can handle incredible amounts of data at scale.
But recently, Large Language Models (LLM) developers have been exploring open-source observability options. Why? We have some answers.
1. Datadog Pricing Surge with Scale
Developers working in large companies have been complaining about the increasing costs and bill shocks with Datadog as their companies scale. Many are turning to open-source alternatives to control their overall costs on monitoring infrastructure.
2. The Need for Specialized LLM Observability Tools
Speed is key in the GenAI space. As LLMs continue to make their way into different industries, traditional monitoring is no longer enough. New problems require new solutions in order to facilitate LLM workflows, manage and experiment with prompts, and fine-tune models. Among the LLM observability tools, Helicone is the one of the best option that developers today are choosing.
Customers love us for:
- our dead easy integration
- our flat learning curve
- how fast we ship
- being open-source
- being purpose-built for Large Language Models
- being exceptionally responsive to our customers
The Initial Setup
To integrate with Helicone, you only need to modify two lines of code (we weren’t joking earlier). Here’s where you can sign up.
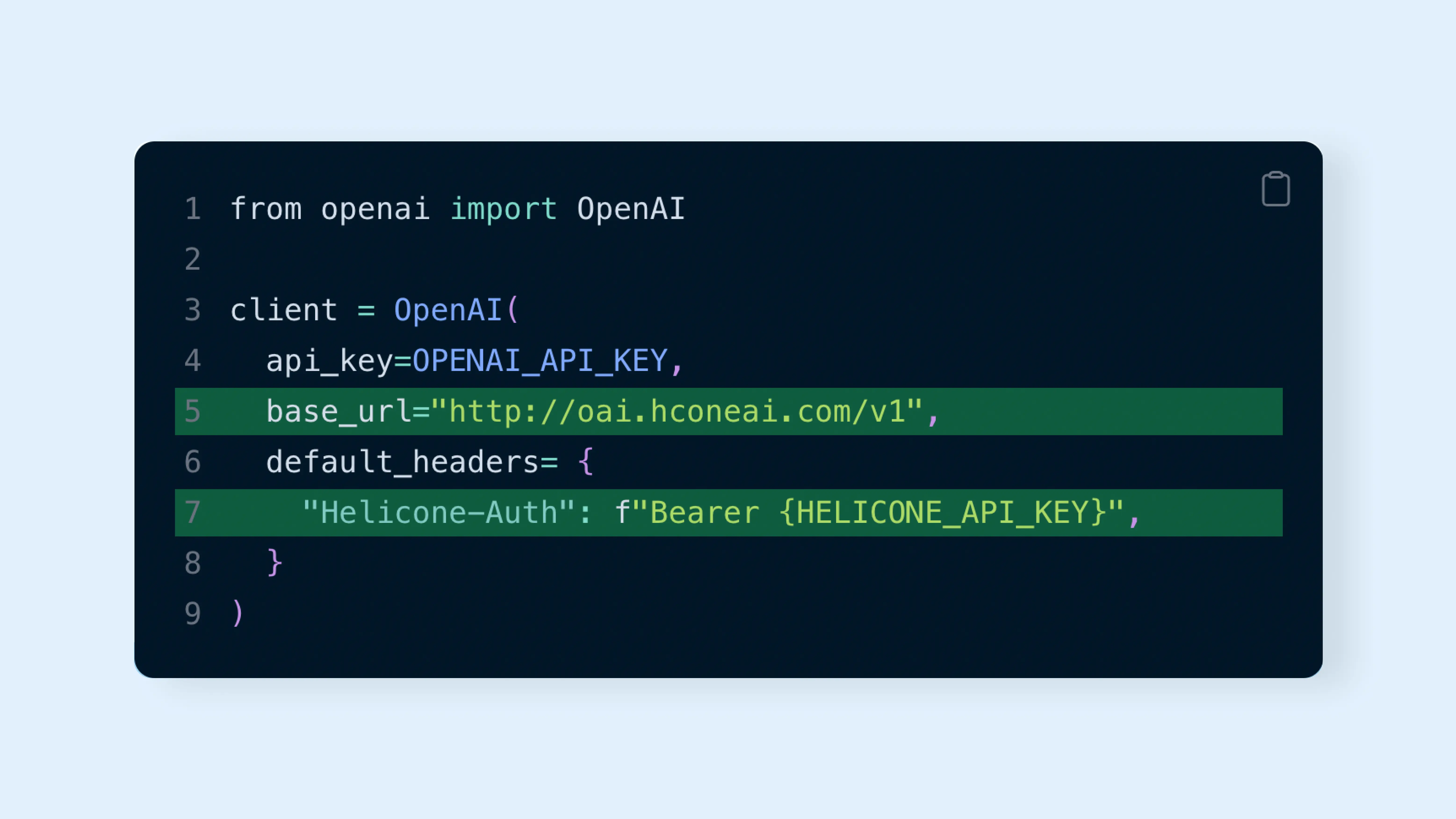
Don’t worry, We walk you through this step during onboarding. Let’s dive into the top three most useful features in Helicone.
3 Most Useful Features in LLM Observability Tools
1. Create Prompt Templates, Run Experiments & Compare LLM Outputs
Testing prompts is hard, but critical. Consider this Tweet on how even minimal changes can significantly affect the accuracy of your output with GPT-3.5 Turbo and Llama-2-70b 5-shot. Helicone makes it easy to maintain and version your prompts, run experiments on prompt variations, and compare key metrics (token count, cost, accuracy, etc.) based on the LLM outputs.
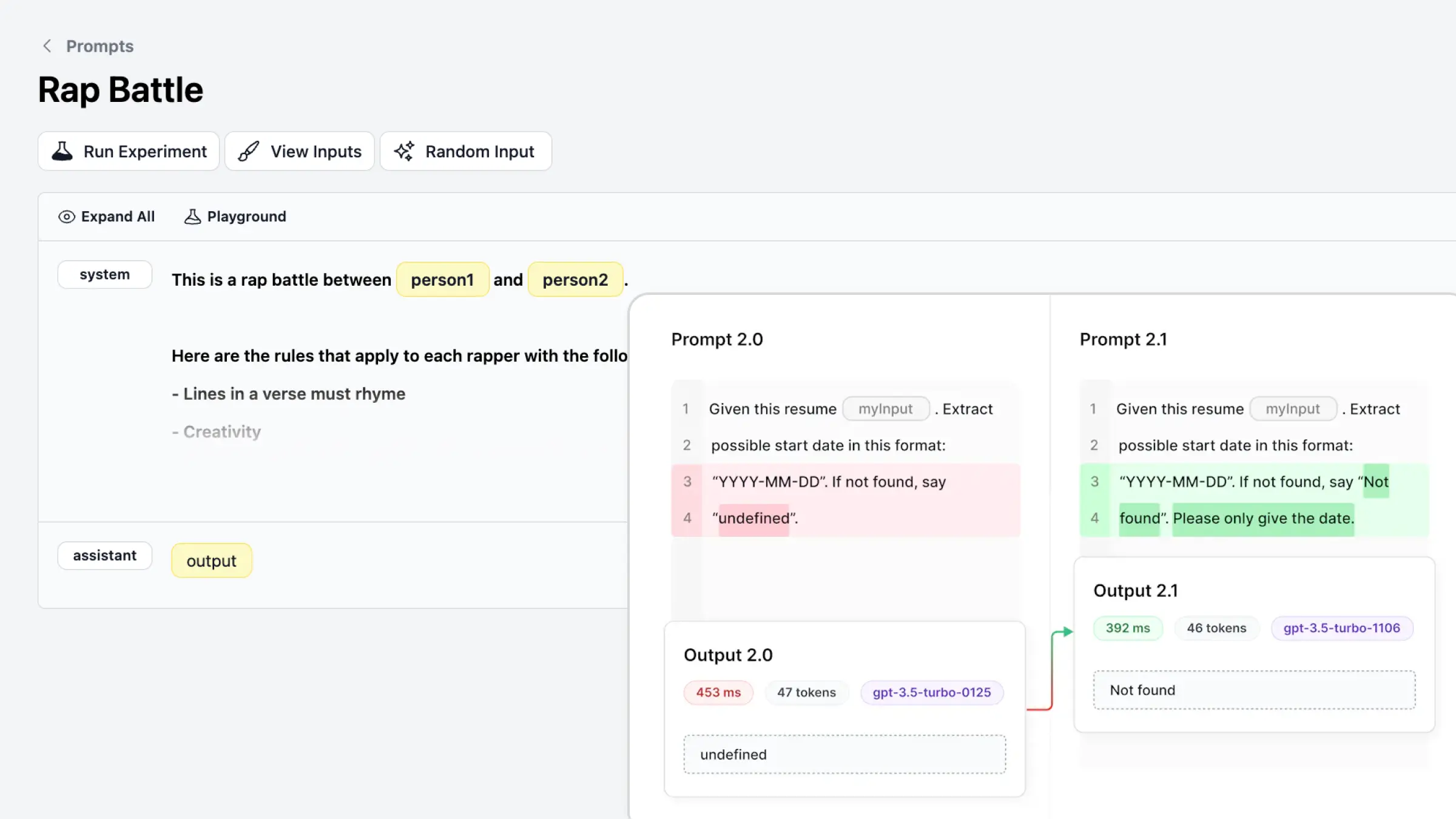
Why our developers love this feature:
- Create as many prompt versions as you want without impacting production data.
- Evaluate the LLM outputs of new prompts (and have data to back you up 📈)
- Test a prompt with specific datasets to save costs by making fewer calls to providers like OpenAI 🤑
- Have full ownership of your prompts. Unlike many other prompt evaluation tools that require you to store the prompt with them, prompts are stored in your code when using Helicone.
You might find this useful:
2. Use Custom Properties to Segment Requests
Custom properties allow you to label your requests and get the total cost or latency over time for this request segment. You can then filter by custom properties to debug, track or organize your requests.
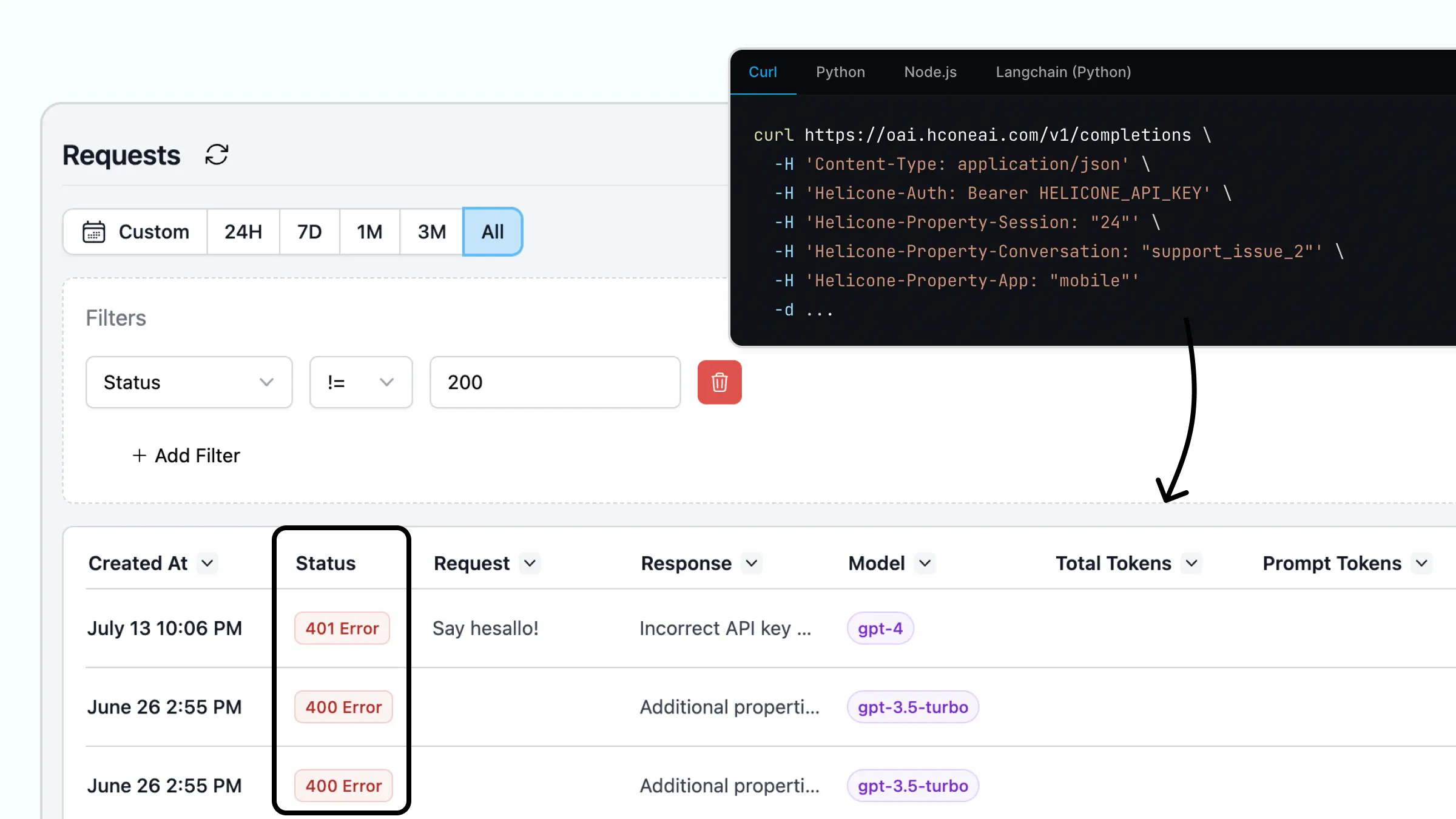
Why our developers love this feature:
- Get the “unit economics”. For example, the average cost of a conversation.
- Slice and dice your requests and metrics by any custom property to pinpoint errors.
- Get the the total cost or latency for a group of requests in a prompt chain
- Segment requests by different environments or different use-cases
You might find this useful:
- Docs: Using Custom Properties in Helicone.
- Blog: How to understand your users better with Custom Properties.
3. Save LLM Costs by Caching on the Edge 🧗
Helicone uses Cloudflare Workers in order to live as close to the edge as possible - guaranteeing minimal latency impact for features like caching. We also precompute results or frequently accessed data to reduce the load on backend resources. By using cached responses, one of our customer was able to save 386 hours in response time.
Why our developers love this feature:
- Faster response, low latency means you can develop your app more efficiently.
- You save money by making fewer calls to OpenAI and other models.
- Better user experience for your users
You might find this useful:
We use Datadog, too
Datadog is designed for infrastructure and application performance monitoring, rather than specifically for LLM observability needs. Our engineers at Helicone use and love it for error detection, setting up alerts, and aggregating metrics across our infrastructure. One key difference is that Datadog is ideal for technical users, whereas Helicone is intuitive to both technical and non-technical users.
Comparing Helicone vs. Datadog Pricing
We’ve observed that some customers find Datadog to be expensive, especially as usage scales up or if they’re not utilizing all features efficiently. At Helicone, we take pride in our scalable solutions where you only pay for what you use.
We believe in making your life easy
Simplified Integration
Our platform is simple to set up and configure. No installation is required.
Open-Source, Open Transparency
Helicone is open-source, which allows us to stay attuned to the needs of the developer community and address a broad range of use cases and challenges. Being open sources also allows us to build Helicone that integrates seamlessly with your existing tech stack.
Gateway
Helicone is a Gateway that gives you access to caching, rate limiting, API key management, and many middleware and advanced features.
Developer Experience
We’ve worked hard to minimize the learning curve for new users, and we are committed to providing the best customer support.
Could we (Helicone) be a good fit for you?
We’re always happy to answer your questions. Want to chat with the founders? Schedule a call with us.